

Function as a service (FaaS) is a serverless way to execute modular pieces of code on the edge. A Serverless architecture allows users to write and deploy code without the hassle of worrying about the underlying infrastructure.
From the perspective of a user, you can develop an application without worrying about implementing, tweaking, or scaling a server.
FaaS is offered by many cloud providers – AWS Lambda, Google Cloud Functions, IBM Cloud Functions, and Microsoft Azure Functions. Developers can now build modular chunks of functionality that are executed independently, respond to events, and scales automatically – all without building the infrastructure separately!
The below image could explain things a little better!
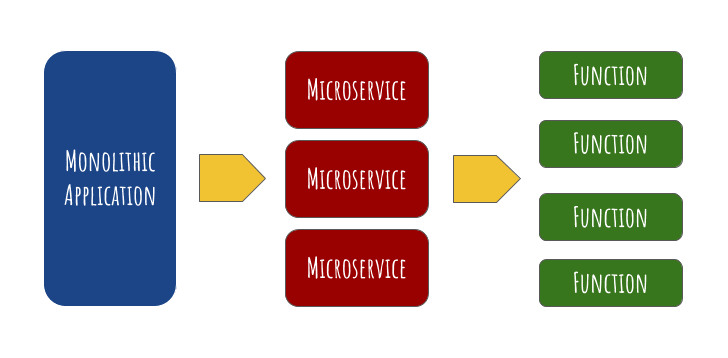
Benefits of FaaS
- Focus on code and functionality – server management is handled by the cloud provider
- Highly available by design
- Scalable – instead of attempting to scale your entire application, your functions are automatically scaled by the usage
- Cost-effective – you pay only when the functions are in use, not when it’s idle
AWS Lambda
AWS Lambda is an event-driven, serverless computing platform provided by Amazon as a part of Amazon Web Services. Node.js, Python, Java, Go, Ruby, and C# are all officially supported as of 2018. In late 2018, custom runtime support was added, which means you can use any language to create a lambda function.
The Cold Start problem
AWS manages the entire infrastructure of Lambda. Each Lambda function runs in its own container. When a function is created, Lambda packages it into a new container and then executes that container on a multi-tenant cluster of machines managed by AWS.
When running a serverless function, it will stay hot as long as you’re running it. After a period of inactivity, AWS will drop the container, and your function will become cold. When the function is invoked again, AWS needs to provision a container to execute your function. So the response time becomes the time to provision the container plus the execution time of your function. So the initialization adds extra latency to your requests.
As seen in the image below, the optimizations are shared between you and AWS.
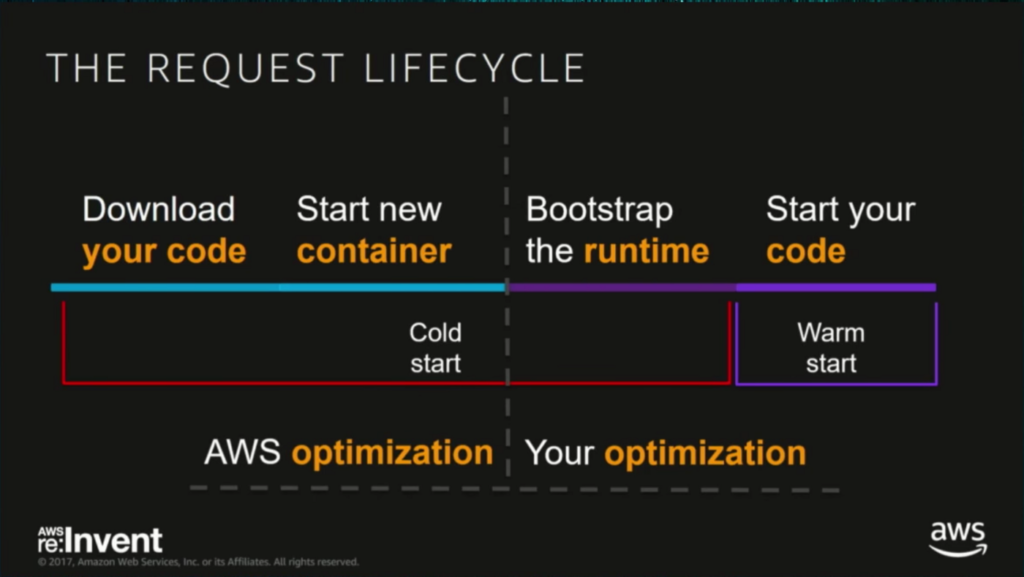
When you use Java to run your functions, the startup time includes the JVM startup time, which increases the latency.
JVM startup delay is mostly contributed by the below factors:
- Loading classes to memory
- JVM runs the code in interpreter mode initially, and after many runs, the JIT compiler can optimize the byte codes to native code which runs faster.
With Java, a better option is to use GraalVM Native Image which allows to ahead-of-time compile Java code to a standalone executable. And now that AWS lambda supports custom runtimes, this is very easy to do especially with the use of a framework like Quarkus. The application startup time can be reduced to milliseconds!
Quarkus
Quarkus is a full-stack, Kubernetes-native Java framework made for Java virtual machines (JVMs) and native compilation, optimizing Java specifically for containers and enabling it to become an effective platform for serverless, cloud, and Kubernetes environments.
Quarkus is designed to work with popular Java standards, frameworks, and libraries like Eclipse MicroProfile and Spring, as well as Apache Kafka, RESTEasy (JAX-RS), Hibernate ORM (JPA), Spring, Infinispan, Camel, and many more.
Quarkus also offers libraries to make it easy to test the lambda functions locally before actually deploying them to AWS.
Quarkus was built around a container-first philosophy, meaning it’s optimized for lower memory usage and faster startup times in the following ways:
- First-class support for Graal/SubstrateVM
- Build-time metadata processing
- Reduction in reflection usage
- Native image preboot
With Quarkus native images, you can use Java for development and not worry about the cold start problem. Quarkus also makes local testing painless.
Quarkus is sponsored by Red Hat, which might make it easy to convince the upper management to give it a try!
Serverless Framework
Quarkus provides good support for AWS SAM by auto-generating the templates, but let’s try another popular way to deploy and test our functions!
The Serverless Framework is a free and open-source web framework written using Node.js and supports various FaaS providers including AWS Lambda, Microsoft Azure Functions, Google Cloud Functions, etc.
You can test your functions locally, deploy or remove them with a single command, and leverage the various community plugins.
Install Node.js if you don’t have it installed already.
And then install serverless.
npm install -g serverless
DynamoDB
Amazon DynamoDB is a fully managed proprietary NoSQL database service that supports key-value and document data structures. You are paying for the throughput instead of storage, and it can scale automatically and is a great option to use in your serverless application for database needs.
DynamoDB is schema-less and in DynamoDB, a table is a collection of items and each item is a collection of attributes (key-value pair). Primary is the only minimum requirement for a table.
Read capacity unit (RCU): Each API call to read data from your table is a read request. Read requests can be strongly consistent, eventually consistent, or transactional. For items up to 4 KB in size, one RCU can perform one strongly consistent read request per second.
Write capacity unit (WCU): Each API call to write data to your table is a write request. For items up to 1 KB in size, one WCU can perform one standard write request per second.
Amazon API Gateway
Amazon API Gateway is a fully managed service that makes it easy for developers to create, publish, maintain, monitor, and secure APIs at any scale. You can easily expose the Lambda functions as REST APIs. And you only pay when your APIs are in use. There are no minimum fees or upfront commitments and it fits well in the serverless world.
Sample Application
Now let’s build a simple application that uses:
- AWS Lambda
- API Gateway
- DynamoDB
- Quarkus
- Serverless Framework
We will create a very simple Task Manager. You will be able to
- Add Task
- Remove Task
- Get details of a Task
- Get a list of Tasks
The source code is available here.
Bootstrap the application
Head over to code.quarkus.io where you can easily bootstrap your Quarkus application and discover its extension eco-system.
Provide your group id, artifact id, and the build tool. I’m using Gradle for this example. Also select Amazon DynamoDB, AWS Lambda, YAML Configuration from the list of extensions.
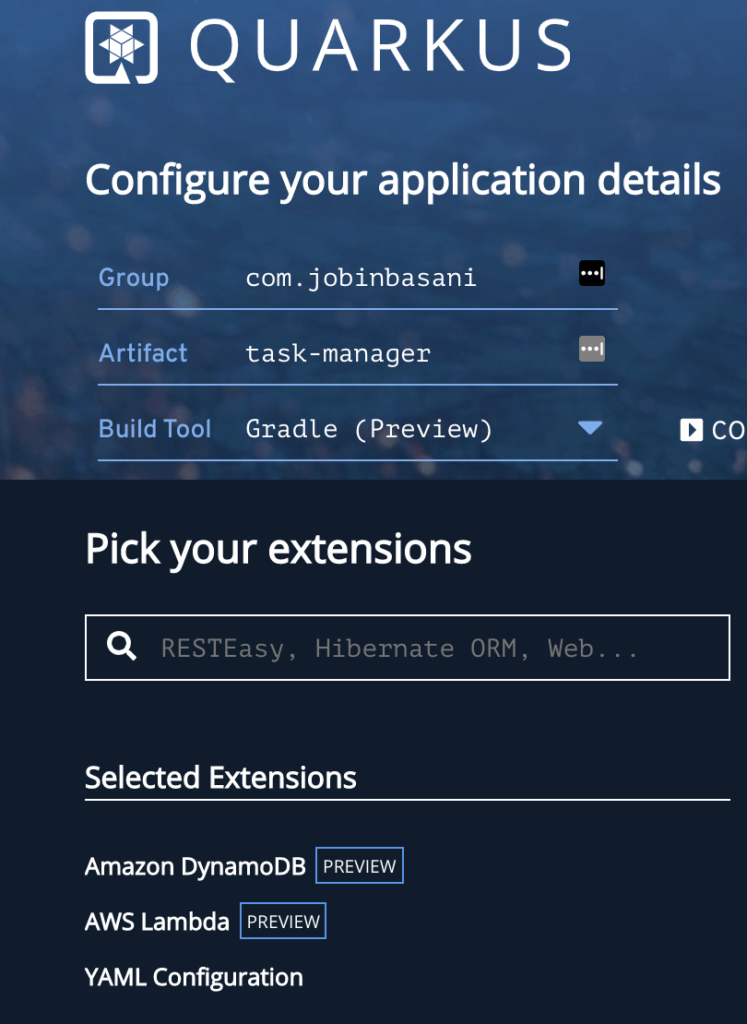
Let’s add a few more dependencies – Lombok for auto-generating some code, a DynamoDB connection client, and Test Containers for integration testing our application, and JsonUnit for testing the JSON lambda responses. You can remove the resteasy and rest-assured dependencies. The list of dependencies looks as below:
dependencies {
compileOnly 'org.projectlombok:lombok:1.18.12'
implementation 'io.quarkus:quarkus-config-yaml'
implementation 'io.quarkus:quarkus-amazon-dynamodb'
implementation 'io.quarkus:quarkus-amazon-lambda'
implementation 'software.amazon.awssdk:url-connection-client'
implementation enforcedPlatform("${quarkusPlatformGroupId}:${quarkusPlatformArtifactId}:${quarkusPlatformVersion}")
annotationProcessor 'org.projectlombok:lombok:1.18.12'
testImplementation 'io.quarkus:quarkus-junit5'
testImplementation "io.quarkus:quarkus-test-amazon-lambda"
testCompileOnly 'org.projectlombok:lombok:1.18.12'
testCompile "org.testcontainers:testcontainers:1.14.3"
testCompile "org.testcontainers:junit-jupiter:1.14.3"
testCompile "net.javacrumbs.json-unit:json-unit-assertj:2.18.0"
testAnnotationProcessor 'org.projectlombok:lombok:1.18.12'
}Interface
Let’s create an interface to define the behavior of our Task Manager application.
public interface TaskService {
Task addTask(Task task);
List<Task> getTasks();
Optional<Task> getTask(String taskId);
void deleteTask(String taskId);
}Lambda Handler
Let’s define the Lambda handler now. Declare a class that implements RequestHandler.
public class Handler implements RequestHandler<TaskRequest, String> {
@Inject
TaskService taskService;
@Override
@SneakyThrows
public String handleRequest(TaskRequest input, Context context) {
switch (getAction(input.getAction())) {
case CREATE_TASK:
return addTask(input);
case GET_TASK:
return getTask(input);
case DELETE_TASK:
return deleteTask(input);
case LIST:
return getAllTasks();
case UNKNOWN:
return null;
}
return null;
}
}Application Configuration
Quarkus supports the notion of configuration profiles. These allow you to have multiple configurations in the same file and select between them via a profile name. Our configurations are defined in application.yml and the profile dependent configuration format is %profile wrapped in quotation marks before defining the key-value pairs. To define a configuration for use when executing the test cases only, we can define as below:
"%test":
database:
docker-image: amazon/dynamodb-local:1.13.2
docker-command: -jar DynamoDBLocal.jar -inMemory -sharedDb
container-port: 8000
table: tasksTable
read-capacity-units: 1
write-capacity-units: 1
quarkus:
lambda:
enable-polling-jvm-mode: true
log:
level: DEBUG
dynamodb:
endpoint-override: http://localhost:8001/
aws:
region: us-east-2
credentials:
type: static
static-provider:
access-key-id: test-key
secret-access-key: test-secretThe dev profile looks as below:
"%dev":
database:
table: tasksTable
quarkus:
dynamodb:
endpoint-override: 'http://host.docker.internal:8000'
aws:
region: us-east-2
credentials:
type: static
static-provider:
access-key-id: test-key
secret-access-key: test-secretServerless Configuration
Serverless configuration is defined in serverless.yml
service: task-service plugins: - serverless-dynamodb-local - serverless-offline
We need two serverless plugins – serverless-dynamodb-local and serverless-offline, both for offline testing and they can be installed by
npm install serverless-offline --save-dev npm install [email protected]
We have a custom section where we define the dynamodb table name, dynamodb local configuration, etc.
custom:
dynamodbTableName: tasksTable
dynamodb:
stages:
- dev
start:
port: 8000
inMemory: true
migrate: trueThe provider-specific configuration goes next. We specify the IAM statements to grant the necessary permissions to perform actions in the dynamodb table. The dynamodb table tasksTable is defined under the resources section and its ARN is dynamically derived using the GetAtt function. The runtime is set as provided since we are building a native image using Quarkus. AWS Lambda expects an executable named bootstrap when a custom runtime is used. We should also set an environment variable DISABLE_SIGNAL_HANDLERS when we use the native image built with Quarkus.
provider:
name: aws
runtime: provided
region: us-east-2
memorySize: 128
timeout: 5
iamRoleStatements:
- Effect: "Allow"
Action:
- dynamodb:Query
- dynamodb:Scan
- dynamodb:GetItem
- dynamodb:PutItem
- dynamodb:UpdateItem
- dynamodb:DeleteItem
Resource:
Fn::GetAtt:
- tasksTable
- Arn
environment:
DISABLE_SIGNAL_HANDLERS: true
DYNAMODB_TABLE: ${self:custom.dynamodbTableName}Now specify the artifact, which will be function.zip that contains the bootstrap executable. This zip file will be generated as part of the Quarkus build.
package: artifact: build/function.zip
Let’s define our DynamoDB table now under the resources section. taskId will be the primary key and we will set the RCU and WCU to be 1.
resources:
Resources:
tasksTable:
Type: AWS::DynamoDB::Table
Properties:
TableName: ${self:custom.dynamodbTableName}
AttributeDefinitions:
- AttributeName: taskId
AttributeType: S
KeySchema:
- AttributeName: taskId
KeyType: HASH
ProvisionedThroughput:
ReadCapacityUnits: 1
WriteCapacityUnits: 1Now let’s define the functions. The handler property here is irrelevant since we are using a custom runtime. The input will be passed to the class implementing RequestHandler interface, but since serverless framework requires the property now, I’m setting it to be the fully qualified name of the Handler class. We are also using the events property to create an http endpoint with lambda integration. A mapping template is also defined which creates an appropriate input for the lambda.
functions:
add-task:
handler: com.jobinbasani.handler.Handler
events:
- http:
path: task/add
method: post
integration: lambda
request:
template:
application/json: >
#set($inputRoot = $input.path('$'))
{
"taskName": "$inputRoot.taskName",
"action": "CREATE_TASK"
}
response:
headers:
Access-Control-Allow-Origin: "'*'"
Content-Type: "'application/json'"
template: >
#set($inputRoot = $input.path('$'))
{
"result": $inputRoot
}The above function will result in an API Gateway method at the path task/add that accepts a JSON like the one below:
{
"taskName":"Task 1"
}This JSON will be transformed as below(as per the mapping template we defined) and submitted to the lambda function.
{
"taskName":"Task 1",
"action":"CREATE_TASK"
}The response will also be a JSON that wraps the lambda response under the result key.
Build
To create a dev build for local testing, run the gradle command below:
./gradlew clean build -Dquarkus-profile=dev -Dquarkus.package.type=native -Dquarkus.native.container-build=true
A prod native build can be created with the below command:
./gradlew clean build -Dquarkus.package.type=native -Dquarkus.native.container-build=true
With the dev build, the dev profile is used which uses the local DynamoDB URL instead of the AWS DynamoDB.
Testing
Quarkus provides good support for unit testing the Lambda functions. For integration testing, we use TestContainers which provides a neat way to run DynamoDB locally in a Docker container and use it for all test cases. We can make use of io.quarkus.amazon.lambda.test.LambdaClient to call our Lambda functions locally within a JUnit test case. The JSON responses can be tested using JsonUnit, a library to perform matches in JSON.
A sample test case looks like the one below:
@Test
public void testCreateAction(){
String taskName = "New Task";
TaskRequest request = new TaskRequest();
request.setAction(REQUEST_TYPE.CREATE_TASK.toString());
request.setTaskName(taskName);
String outputJson = LambdaClient.invoke(String.class, request);
assertThatJson(outputJson)
.inPath("$.taskName")
.isEqualTo(taskName);
}Serverless framework can also be used to test the lambda functions.
Start the local dynamodb server.
sls dynamodb start --migration
The --migration option will run the database migrations upon start i.e will create the required tables as defined in serverless.yml
Invoke the lambda function with JSON data as below:
sls invoke local -f tasks-manager --data '{"action":"CREATE_TASK","taskName":"Task 1"}' --stage devYou should be able to see the JSON response of lambda execution.
Deployment
To deploy our lambda function, create a prod build first
./gradlew clean build -Dquarkus.package.type=native -Dquarkus.native.container-build=true
Now, use the deploy option of serverless framework.
sls deploy
You will see an output similar to the one below:
Serverless: Packaging service... Serverless: Creating Stack... Serverless: Checking Stack create progress... ........ Serverless: Stack create finished... Serverless: Uploading CloudFormation file to S3... Serverless: Uploading artifacts... Serverless: Uploading service function.zip file to S3 (16.29 MB)... Serverless: Validating template... Serverless: Updating Stack... Serverless: Checking Stack update progress... .................................... Serverless: Stack update finished... Service Information service: task-service stage: dev region: us-east-2 stack: task-service-dev resources: 13 api keys: None endpoints: POST - https://awshost.execute-api.us-east-2.amazonaws.com/dev/task/add functions: tasks-manager: task-service-dev-tasks-manager layers: None
You can now test the endpoints printed in the output above using a tool like Postman or cURL.
To remove the functions, just run
sls remove
To update a function, you can run the deploy command again. You don’t need to remove it first.
Source Code
Full source code is available here